Over the weekend when my Windows 10 decided to completely go nuts. Ok it was my fault, as it happened after some exploitation attempts. But during the re-install I ran into a small issue. When trying to re-install on my NVME drive the setup kept stating that “Couldn’t create partition or locate an existing one in Windows 10“.
In regards to that error there were some hints out there about using diskpart to clean/”resetting the disk” which I didn’t want to do, as I had things I wanted to keep on other partitions.
Fortunately I got away with only deleting the all the Windows related partitions on that disk. Namely I deleted the windows partition itself & 2 recovery related partitions – so all I had left was the data partition. After doing that my windows installer stopped throwing that error and went on without any issues.
As it turns out that Nessus Essentials is having trouble sending out e-mails. Ran into it after installing Nessus on a Kali VM. Filled out the form and although Nessus stated, that e-mail sent successfully, no message arrived. Not even after a few more attempts. Fortunately there is a quick work around, I wish I just had turned to Tenable’s website a bit sooner. To activate Nessus Esstentials just use Tenable’s own website to request the activation code. Just go fill out the form at https://www.tenable.com/products/nessus/activation-code and don’t wait for the one from your own installer, as it probably will never arrive.. Happy Scanning!
In quite a few servers that I’ve managed to gain access to during pen-tests I have found issues in filesystem permissions. The type of permission issues that end up with me gaining root privileges, aka privilege escalation.
When you gain access to a server it always seems to be a good idea to check the crontab log’s. If you have access to them and you if you see any of the scripts running in with the root user permissions.
If you find any root/other useful user entries in the logs, then go and check scripts filesystem permissions. Quite often I have stumbled upon a root script that can be modified by the “service users”. I don’t exactly know why, put some people have scripts with “apache/ww-data” write permissions run by root.
That is just a bad idea on so many levels. How-come people don’t realize that having root run what ever normal user’s scripts gives instantly root privileges to that user.
This is a short write up of a old flaw I reported to Cisco years ago to which they replied it’s that they see no issue there.
When doing a security audit at a client I stumbled upon a Cisco-WSA/11.5.2-020 appliance filtering HTTP traffic. As it’s the first encounter for me with sucha device, the first thing that came to my mind when seeing that header in HTTP responses was, how can I abuse this. As it turns out I actually could abuse it.
Setup description
It is a small corporate network with a few different segments separated by a firewall with a really strict access policy. Client computers don’t have access to the management network only access to specific internal applications and the internet.
All internet bound HTTP requests are sent by the firewall to the Cisco WSA by using “policy based routing”. that client computers network from which all internet HTTP traffic gets redirected to the Cisco WSA by the firewall.
The Issue
The clients firewall was blocking access to their management network from the users segment as it should. But I was able to bypass the firewall rules by adding a extra header to HTTP requests and effectively map all the hosts in their management network. As it turned out they had too much trust in their Cisco appliance and firewall rule set and thought you don’t need to create “deny to internal” rules on the WSA. But that provided them with a false sense of security.
In the case of this setup, when you add a extra “Host: x.x.x.x” header the firewall wont know the true connection destination thus won’t be able to actually do it’s job. As it will see your computer connecting to the IP address of the original query destination. At the same time the Cisco WSA device ignores the connection that your firewall thinks you are opening actually establishes a connection to the secondary host header. That effectively bypasses your firewall policy giving and purely relies on what policies you have set in the WSA. An example from the notes I have from that time:
C:\>curl -kv http://google.com --header host:"192.168.90.1"
* Rebuilt URL to: http://google.com/
* Trying 216.58.210.174...
* TCP_NODELAY set
* Connected to google.com (216.58.210.174) port 80 (#0)
> GET / HTTP/1.1
> host:192.168.90.1
> User-Agent: curl/7.55.1
> Accept: */*
>
< HTTP/1.1 301 Moved Permanently
< Location: https://192.168.90.1/
< Transfer-Encoding: chunked
< Date: Mon, 23 Aug 2021 12:16:19 GMT
< Via: 1.1 wsa.ent.int:80 (Cisco-WSA/11.5.2-020)
< Connection: close
<
* Closing connection 0
As you can see, I originally queried google.com, but WSA actually returned to me the HTTP response from an internal host. In that case it was the management network where the WSA management interface resides. Using that “Host” header, I could map their whole network. When the IP address I chose didn’t have a listening tcp port 80, then the connection was closed, when it existed it returned the HTTP page/response from the hidden server or when the host didn’t exist it timed out.
Although this looks bad, then it gets worse.. At least for that client. In their case they actually had a switch that had it’s web management over HTTP open and with default credentials. It turned out it was the same switch I was connected to, so I was able to reconfigure the port where I was connected to be directly in the management network.
Final thoughts
Although most of the things that I reported to the client probably could have been avoided by having changed their switch admin password and having also a strict “deny all inbound HTTP” traffic from that specific user segment rule on the WSA (not sure, if it would have triggered). Then still in my honest opinion the fact that the WSA device actually connects to the added host header, while all other devices in the connection chain see that the client is going to some innocent place is just wrong. Probably a lot of implementations can fall victim to this oversight in the policy as normal policy testing will never find such a loop hole.. When directly trying hidden/internal hosts you get time outs, when you add them to the header “voila it works..”.
Today I was reminded of a little Pen-Test I did last year, which reminded me that I should write why for me that feature seems like a bad idea most of the times.
Zabbix is a popular monitoring solution which is agent based and it has the ability to run remote commands on the agents. While it may be nice to have your monitoring system try and auto restart things, etc. Enabling that feature also has other consequences, that people fail to take into account or just ignore.
Namely that it opens up a whole new nice attack vector to easily gain foothold in your servers. One issue is that usually the monitoring service instances are not that well protected. In a lot of cases the reasoning behind that is that “it’s just monitoring, there nothing sensitive there”. Although I disagree on that part, not going to rant about that. That statement becomes completely wrong as soon as you enable the remote command ability on the agents.
So what harm can come from the remote command feature? Why is it bad? In one of my Pen-test engagements I used it to take over the client’s whole infrastructure. Although it’s “just a monitoring solution”, gaining access to it was enough to compromise all of their servers thanks to the remote command feature. How I got access to their monitoring system is one thing, they had multiple setup failures there, but that’s besides the point. Never have devices with admin access to any system lying around unprotected in your office.. IE monitoring dashboard meant to show your service status in the reception area in your office..
Not to be too technical, but here is a short description of what happened. Basically after having gained access to the monitoring dashboard and noticing it had Zabbix admin privileges I did the following: * Tested whether remote command execution was enabled on some hosts, that turned out to be YES. * Using that figured out which of their servers had outbound unrestricted internet access. * Activated a simple remote shell on the internet capable devices, just to make my life easier * Found out their systems patch levels via Zabbix and abused a existing sudo vulnerability to gain root privileges
Long story short.. Just think twice about activating that feature and maybe there is some better way to do what You need. Oh yeah and patch your systems, as that sudo vulnerability at that time was already quite old.
A client was concerned that Apache/OpenSSL combo was not respecting certificate key usage values out of the box. They demonstrated how they logged into a web-service using certificates that didn’t have the “TLS Web Client Authentication” extended key usage set. Because of that were asking if they had some config error and how would it be possible to require those extensions to be set.
They had messed about with different hints they got from the web, but none worked properly. After a bit of reading manuals/researching the web and tinkering around I managed to get it working the way they wanted it to. So I thought I’d share the brief config snippet to help out anyone else who was running into the same problem.
<Directory /var/www/html/test.site/tls_test>
SSLVerifyClient require
SSLVerifyDepth 2
SSLOptions +StdEnvVars
Require expr "TLS Web Client Authentication, E-mail Protection" in PeerExtList('extendedKeyUsage')
When booting up a older Kali VM I hadn’t used for a while, I wanted to update it & ran into a small issue. Namely whilst trying to update I ran into the following error message:
root@kali:~/Documents# apt-get update Get:1 http://kali.koyanet.lv/kali kali-rolling InRelease [30.5 kB] Err:1 http://kali.koyanet.lv/kali kali-rolling InRelease The following signatures were invalid: EXPKEYSIG ED444FF07D8D0BF6 Kali Linux Repository devel@kali.org Reading package lists… Done W: An error occurred during the signature verification. The repository is not updated and the previous index files will be used. GPG error: http://kali.koyanet.lv/kali kali-rolling InRelease: The following signatures were invalid: EXPKEYSIG ED444FF07D8D0BF6 Kali Linux Repository devel@kali.org W: Failed to fetch http://http.kali.org/kali/dists/kali-rolling/InRelease The following signatures were invalid: EXPKEYSIG ED444FF07D8D0BF6 Kali Linux Repository devel@kali.org W: Some index files failed to download. They have been ignored, or old ones used instead.
As it seems, the GPG key had been changed. Fortunately the fix is easy, just do the following:
Download it using the wget command or via browser: wget https://http.kali.org/kali/pool/main/k/kali-archive-keyring/kali-archive-keyring_2020.2_all.deb
Install it by running “pkg -i kali-archive-keyring_2020.2_all.deb” root@kali:~/Documents# dpkg -i kali-archive-keyring_2020.2_all.deb (Reading database … 528672 files and directories currently installed.) Preparing to unpack kali-archive-keyring_2020.2_all.deb … Unpacking kali-archive-keyring (2020.2) over (2018.2) … Setting up kali-archive-keyring (2020.2) … Installed kali-archive-keyring as a trusted APT keyring.
A long time ago, when I decided to get the EC Council “Certified Ethical Hacker” certification done, I couldn’t imagine what type of job offers and requests I would start getting after adding it to my Freelancer profile. People started asking me about a lot of illegal things. And over the years nothing has changed, still almost every day I get some strange requests I now just tend to ignore, not even turn down with a reply.
Initially it seemed strange to receive on a daily basis requests to break into some ones Facebook, Twitter or Instagram account or bug their smart device. Eventually I got used to it, but still some of the requests are stranger than others and make me scratch my head..
Mostly people ask to spy on their life partners/family/close ones, because they think they are being cheated on and to them this makes the privacy invasion & illegal actions ethical. Those are just the regular everyday ones and somewhat relatable as an emotional outburst- yet still a bit creepy people go that far instead of just confronting the issue. But besides these regular ones there are the strange ones.
One day I got a request asking whether it would be possible for me to remove every negative news article ever made about one specific person from one country’s news sites. Yes all of them from all news papers. That almost got me interested into replying to the request, just to know what they are trying to hide.. But decided not to, just in case.. Then there are requests to “get my money back from a gambling site or some crypto deal”. Or locate who ever is behind what ever gamer tag or social media account and get their personal details..
No those aforementioned requests don’t come via some shady underground forums, but regular freelancer job exchanges. Which makes it seem to me that they actually don’t moderate their postings, even after reporting some illegal postings as illegal they were still up 3 days after the report.
After being bombarded with such requests for a while now, I wish people would actually learn what ethical hacker means and deal with their problems in a LEGAL way. Also I wish that freelancer sites would actually deal with the illegal offers on their sites them selves also.
As an ending to this rant, I have to cite the definition for ethical hacker I actually like and that feels right to me. The definition as it is written on techtarget :”An ethical hacker, also referred to as a white hat hacker, is an information security (infosec) expert who penetrates a computer system, network, application or other computing resource on behalf of its owners — and with their authorization.”
WordPress is a very popular engine to use when creating your businesses website, it’s flexible, etc. But when finding a developer to create your page, please find some one who actually thinks about security also not only the design. Or have some one take a look at it afterwards.
A lot of company websites I’ve seen have no security plugins installed and very lax settings. They don’t get updated and some even have out right data leaks in them.
What made me write this was one of the latest & interesting security practice I saw one developer use. What he did right, was use complex passwords! But where he went wrong, was he was using it also as a username. Although using a completely random 12 character username is in some sense good (no dictionary attack for it) and it should be really hard to guess.. Well except when you have WP JSON interface wide open to the public. Guess what, the username is there & when you reuse your password like username actually for the password, its all over..
For me when I’m tasked at looking at a Website’s security, the first thing I look for is are there any hints on credentials through known interfaces that haven’t been locked down properly. Why even bother trying to find injection vulnerabilities when the low hanging things haven’t been taken care of.
So please when running your website on WordPress, do the decent thing and lock it down to keep your viewers/customers safe. Invest a bit of time in securing your site and reading on how to do it.
Here are some basic hints: * Install some security plugins, for example WordFence or iThemes security. * Disable un-needed features/interfaces that you don’t use. (ie wp-json/xmlrpc) * Don’t have your WP-ADMIN page open to the public move it / add some extra measures to protect it. (basic auth/MFA, etc) * Keep your plugins/WP instance up2date. * Do regular backups (off-site) & track file changes to be able to spot malicious actors more easily and have a clean site you could restore. * Don’t reuse passwords – I’ve been able to access too many admin pages using passwords from password leak databases to say that this isn’t a problem. * Check if your e-mail address has been a part of any password dumps (https://haveibeenpwned.com)
As with many people I had moved to SSD drives a long time ago for main active storage and almost forgot about HDD’s. I kept some of my old HDD-s active for dumping data that I didn’t need to access so quickly/often. But now that my 9 years old 2TB Hitachi disk is showing signs of its death approaching (rattling sounds/SMART errors) it has finally come time to replace it.
Price check HDD vs SSD
I initially thought that SSD’s have been around long enough so their prices might be reasonable.. Oh how wrong was I. If you need ample space to store all your “password lists, strange old Linux version compilation machines and test hack test boxes”, then SSD-s are still not reasonable at all. What actually surprised me was that the “slow” SATA SSD-s are priced the same as M2 NVME drives.
A 4TB SATA SSD will set you back 300-700 EUR. So if you don’t care about spending money on data that just mostly sits around, be my guest, but at least for me it seemed a waste. So I started looking at HDD prices and they were much more reasonable. Starting from as low as 75 EUR and ranging up to ~250EUR for 4TB.
After a bit of looking around on the market for disks that seem to have “long term survivability”, a reasonable price and availability, I ended up choosing the 4TB Seagate IronWolf Pro. It cost me ~120 EUR, so not bad at all.
Performance
Yes I know it’s a NAS oriented drive and I’m currently putting it inside my “regular computer”. But as my PC is “like a server” and it’s always on doing something.. Then, the fact that the disk has a long MFTB (1,2M hours) and is rated for 24/7 work is important to me.
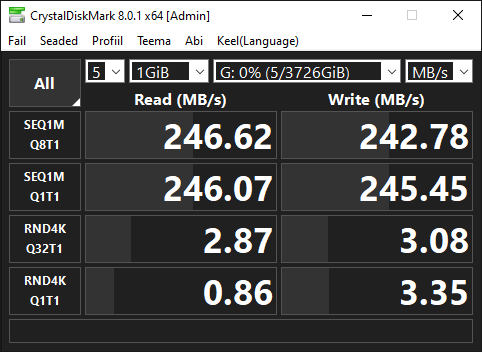
After having installed the drive, it actually surprised me. When Seagate’s tech spec PDF states that it’s read/write speed should be 220MB/s, it out performs it. CrystalDiskMark results say that it’s actually 246MB/s read and 242MB/s write.
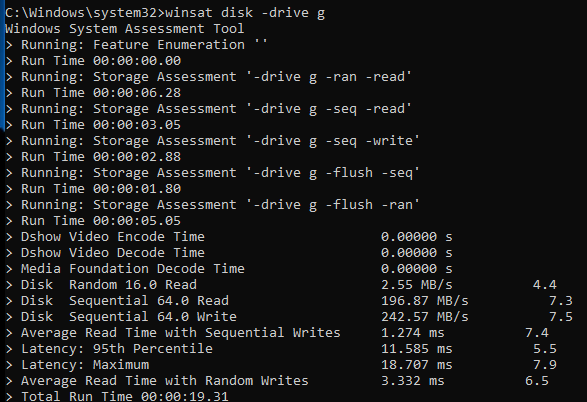
Also tried measuring disk performance with the build in Windows System Assessment Tool. It showed a bit slower results on the read. Did 10 runs and this was ~the average:
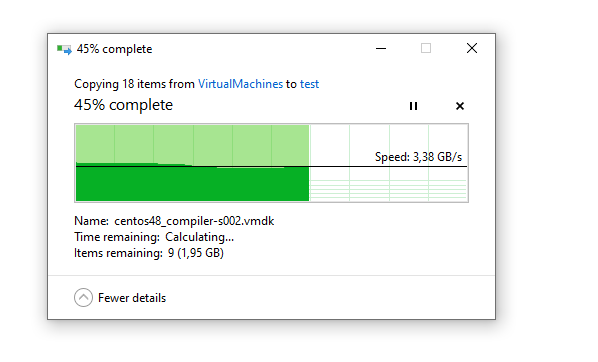
Besides that, I was surprised that copying stuff there from my NVME drives was “almost instant”.. I guess Windows is doing some magic in the background with newer drives. When I copied a few VM-s from my NVME to the IronWolf 10GB “was done in a few seconds”. Tested it a couple of times “over and over again” with always the same results:
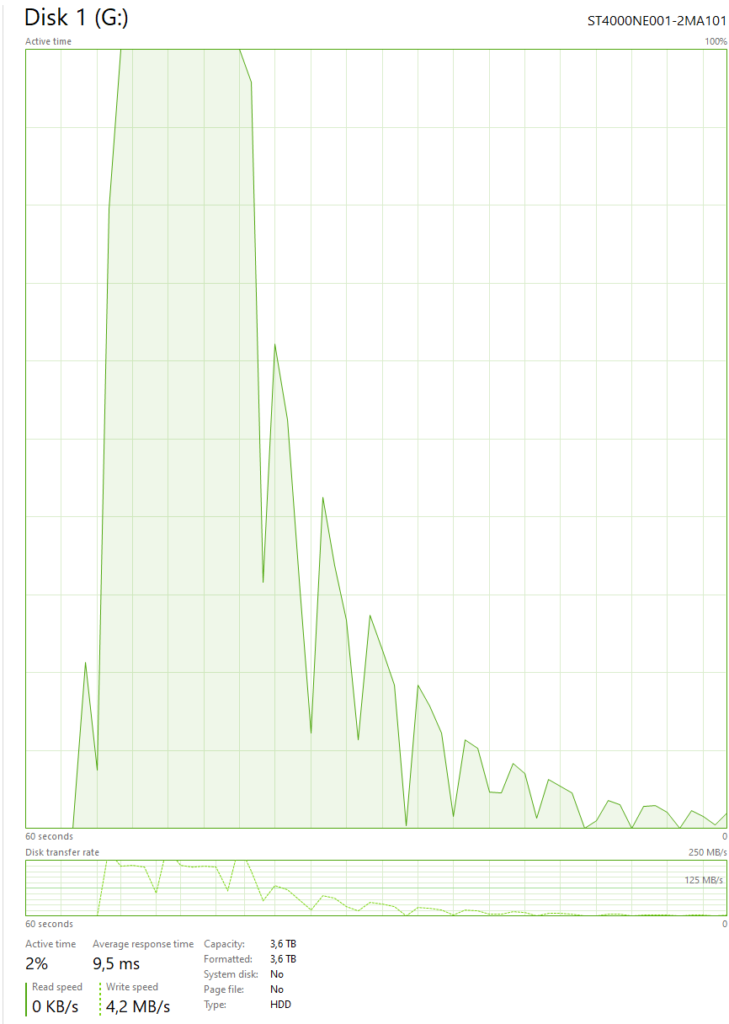
And yes I know that the data wasn’t actually written that fast to the disk that fast. But it still surprised me and was interesting to see this behavior. When looking at task manager steady data transfer could be seen even after explorer had stated that it had finished copying the files:
That did not happen when I copied the same things to one of my older WD Black HDD’s that isn’t yet dying.
Conclusion
I was sad to see that the SSD prices are still high when you need higher capacity. But I was pleasantly surprised at the read/write performance of todays HDD’s. They actually come really close to cheaper SSD drives. When you add in the price per GB/TB then I completely understand why people still build machines which have a relatively small SSD for the boot drive and a HDD larger amounts of data.